About our cloud
A few weeks ago we started private cloud installation based how we broke our OpenStack. We chose our hardware provider and decided to use CentOS 7 and Juno release.
We wanted it to be as flexible and easy to expand as possible so we used Puppet OpenStack modules available at https://forge.puppetlabs.com/puppetlabs/openstack. Despite some customizations and also wrote our own modules to adapt it to our needs and environment. Using hiera configuration we installed multiple nodes without any problem. For testing purposes we even installed one compute node on Ubuntu 14.04 – it worked like a charm! Encouraged by this little success we decided to push our IaaS to use for our development and testing
The problem
On the day we presented the solution to our colleagues we noticed strange problems during launching instances or reconfiguring tenant networks. It took us a couple of hours to discover that it was a fault of intermittently interrupted communication between multiple OpenStack components with rabbitmq. We managed somehow to force rabbitmq to work and present our cloud to guys, but decided to resolve the issue permanently.
Solution 1
One of proposed solutions was to upgrade rabbitmq to higher version as we found out that the version we had could be affected with bug involving connectivity issues. We upgraded rabbitmq along with the operating system (from CentOS 7.0 to CentOS 7.1).
The next day we found out that the upgrade didn’t help – we still had strange and irregular errors. After further investigation it turned out that there were some issues with network connectivity which led to resetting tcp connections to rabbitmq. We relieved, as we finally managed to use our cloud. At least we thought so…
Not so long after we found another problem – instances did not get IP addresses from dhcp! Another battle had begun
Extensive troubleshootin
This time the problem was much more complicated – it involved one of the most complex OpenStack project – neutron networking.
Our cloud was using GRE tunnels for tenant networks intercommunication. It looks similar to the one below.
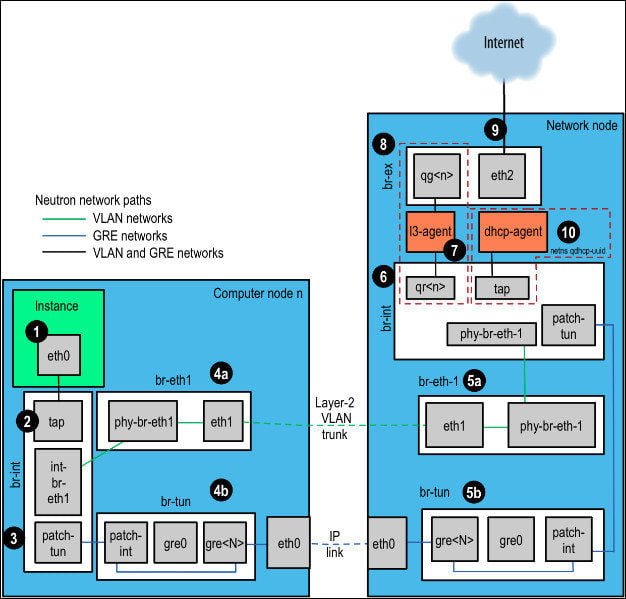 extensive cloud troubleshooting
extensive cloud troubleshootingSo our troubleshooting covered the following areas:
- network namespaces – especially those containing dhcp servers
- iptables security groups implementation
- openvswitch configuration and flows
- gre tunnels communication – establishing, configuration in br-tun
- puppetlabs openstack modules – especially firewall configuration
We used tcpdump. A lot! What we discovered is that traffic flows correctly from instance to network node (from 1 through 4b to eth0), but it didn’t pass to br-tun ovs switch.
This is what we saw on eth0 on compute node:
15:00:35.229282 IP 10.69.0.13 > 10.69.0.10: GREv0, key=0x2, length 350: IP 0.0.0.0.bootpc > 255.255.255.255.bootps: BOOTP/DHCP, Request from fa:16:3e:38:9a:c7, length 300
15:00:41.301798 IP 10.69.0.13 > 10.69.0.10: GREv0, key=0x2, length 350: IP 0.0.0.0.bootpc > 255.255.255.255.bootps: BOOTP/DHCP, Request from fa:16:3e:38:9a:c7, length 300
15:01:02.797726 IP 10.69.0.13 > 10.69.0.10: GREv0, key=0x2, length 350: IP 0.0.0.0.bootpc > 255.255.255.255.bootps: BOOTP/DHCP, Request from fa:16:3e:38:9a:c7, length 300
15:01:12.742899 IP 10.69.0.13 > 10.69.0.10: GREv0, key=0x2, length 350: IP 0.0.0.0.bootpc > 255.255.255.255.bootps: BOOTP/DHCP, Request from fa:16:3e:38:9a:c7, length 300
15:01:23.369777 IP 10.69.0.13 > 10.69.0.10: GREv0, key=0x2, length 350: IP 0.0.0.0.bootpc > 255.255.255.255.bootps: BOOTP/DHCP, Request from fa:16:3e:38:9a:c7, length 300
15:01:53.990728 IP 10.69.0.13 > 10.69.0.10: GREv0, key=0x2, length 350: IP 0.0.0.0.bootpc > 255.255.255.255.bootps: BOOTP/DHCP, Request from fa:16:3e:38:9a:c7, length 300
It seemed like packet was being sent properly through GRE tunnel. After a while we tried to manually inject firewall rule to allow gre traffic on all nodes:
iptables -I INPUT -p gre -j ACCEPT
And it worked! The question was why it is now required? It worked fine without it before.
We even traced a firewall rule that should permit all traffic in management network:
-A INPUT -s 10.69.0.0/16 -m comment --comment "8999
- Accept all management network traffic" -m state --state NEW -j ACCEPT
Solution 2
Of course we reviewed all changes. CentOS 7.0 to 7.1 upgrade was the first suspect. Beside rabbitmq no OpenStack were updated. We found however that kernel package was upgraded. After we downgraded kernel to version 3.10.0-123.20.1.el7.x86_64 we didn’t need to include this additional firewall rule for GRE tunnels to work. While the case is still under investigation it is sure that this is broken CentOS 7.1 (1503) kernel to blame. Probably related to recent iptables/conntrack module changes. Our cloud is now alive and we are happy and richer with new experience.
What we have learned
It was a great, but also a hard lesson for us. We found out that:
- it’s better to solve one issue at a time
- upgrade is not the best way to solve your problems
- security groups are designed in a way that omits dhcp queries – they are excluded at the very beginning
- you shouldn’t use 3rd party modules without reviewing and understanding their concepts – they can be designed for particular scenario only
Thanks Patryk Malina and Marcin Piebiak for carrying out the installation and this cumbersome troubleshooting! :-)
Powiązane wpisy:
Nowa odsłona OpenStack: Red Hat OpenStack Platform 10