Jednym z większych ryzyk przy podnoszeniu wersji bazy danych PostgreSQL, jest brak kompatybilności aplikacji z nowym wydaniem bazy danych. Zwłaszcza jeśli chcemy zmigrować bazę z wersji o kilka lat i wiele wydań starszej, np. z 9.2 do 11. Standardowym podejściem jest wgranie bazy produkcyjnej na serwer testowy z nowszą wersją bazy i oddanie jej do testowania – testerom czy nawet użytkownikom końcowym. Rzadko jednak ścieżki testowe pokrywają wszystkie możliwe ścieżki dostępne w aplikacji, co stwarza ryzyko wystąpienia błędu na produkcji, jeszcze rzadziej mamy możliwość zbadania zmiany wydajności pomiędzy starszym i nowszym wydaniem serwera. To i przyczyny takie, jak brak zasobów ludzkich przyczyniają się do przeciągania w czasie decyzji o ewentualnym upgradzie czasem nawet o wiele lat.
A przez ten czas tracimy często bardzo wiele. Nowsza wersja Postgresa oznacza zwykle:
- nowe funkcjonalności,
- zwiększoną wydajność,
- ulepszoną diagnostykę i monitoring,
- poprawę błędów,
- przedłużenie wsparcia (nowa wersja jest wspierana przez 5 lat).
Pełna regresja
W tym artykule opiszę sposób wykonania pełnych, zautomatyzowanych testów regresyjnych pozwalających wychwycić wszystkie lub większość (w zależności od czasu zbierania logów) niezgodności występujące na nowej wersji bazy PostgreSQL bez zaangażowania testerów.
Jak to często bywa w przypadku Postgresa, wszystkie wymienione w artykule narzędzia są darmowe, a ich kod jest ogólnodostępny.
 Illustration 1: Schemat wykonywania testów regresyjnych przed podniesieniem wersji
Illustration 1: Schemat wykonywania testów regresyjnych przed podniesieniem wersjiŚrodowisko
Pierwszym elementem, którego potrzebujemy, jest oczywiście środowisko, na którym możemy wykonać testy. Instalujemy tam wersję Postgresa, do której chcemy podnieść bazę np. dla systemu CentOS 7 i wersji PostgreSQL 11 wykonamy poniższe polecenia:
yum install -y https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install -y postgresql11 postgresql11-server
Następnie inicjalizujemy i uruchamiamy nowy klaster w wersji 11:
/usr/pgsql-11/bin/postgresql-11-setup initdb
systemctl start postgresql-11
Opcjonalnie dodajemy automatyczny start usługi:
systemctl enable postgresql-11
Zbieranie logów
Teraz gdy mamy już klaster i nowe binarki w wersji 11 potrzebujemy danych z bazy produkcyjnej. W związku z tym, że podnosimy wersję bazy o co najmniej jedną główną wersję, tzw. major potrzebny jest nam dumplogiczny (nie fizyczny!).
Dokładnie od momentu zrobienia snapshotu bazy możemy zacząć gromadzić zdarzenia, które dzieją się na bazie w celu późniejszego ich „odegrania” na nowej wersji. Zdarzenia te gromadzimy w formie logu tekstowego (nie WAL!), czyli na ogół tego, co znajduje się w katalogu log lub w starszych wersjach pg_log. Pliki logu tekstowego będziemy parsować narzędziem pgreplay. Jak każdy parser pgreplay ma swoje wymagania co do formatu logu przyjmowanego na wejściu. Najlepiej jest dostarczyć mu logi w postaci pliku csv, tj. parametr log_destination ustawiony na csvlog. Poza tym narzędzie wymaga ustawienia także poniższych parametrów w pliku konfiguracyjnym:
log_min_messages = error (lub wyższy)
log_min_error_statement = log (lub wyższy)
log_connections = on
log_disconnections = on
log_line_prefix = '%m|%u|%d|%c|' (jeśli nie używasz formatu csv)
log_statement = 'all'
log_min_duration_statement = 0 (tutaj uwaga na przyrost loga!)
lc_messages musi zostać ustawione na angielski, np. C (kodowanie nie ma znaczenia)
Powyższe parametry można skopiować i wkleić na koniec pliku postgresql.conf. Następnie wykonujemy reload klastra produkcyjnego w celu załadowania nowej konfiguracji logowania. Dobrze jest również zmienić dotychczasowy plik logowania na nowy, w przeciwnym razie w jednym pliku będziemy mieć logi zarówno w starym, jak i nowym formacie co utrudni późniejsze parsowanie:
SELECT pg_rotate_logfile();
Co prawda „nagrania loadu” potrzebujemy dopiero od momentu zrobienia dumpa, ja jednak wolę ustawić logowanie przed zrobieniem dumpa, wówczas mam pewność co do tego, że wszystkie zdarzenia od momentu rozpoczęcia dumpa logicznego zostaną zarejestrowane w poprawnym dla pgreplaya formacie (bez żadnej „dziury” w workloadzie).
Ważną zasadą jest to, żeby zawsze używać nowszej wersji binarek (czyli w tym przypadku pg_dumpa z nowej, 11 wersji Postgresa).
Przystępujemy do wykonania dumpa z produkcji. Na serwerze testowym, posługując się nową binarką pg_dump wykonujemy:
/usr/pgsql-11/bin/pg_dump -h produkcja nazwa_bazy > dump_ze_starej_wersji.dmp
Zbieranie logów
Najdłuższy moment całego procesu.
W zależności od tego, jaki cykl ma nasza aplikacja oraz z jaką dokładnością chcemy wykonać test, czekamy, aż nazbieramy odpowiednią ilość logów. Zwykle logi z miesiąca działania systemu są wystarczające. Dla niektórych systemów da się skrócić ten czas do tygodnia – tutaj zadecydować musi osoba dobrze znająca system od strony biznesowej.
Nie zapomnijcie zabezpieczyć odpowiednio dużo miejsca na logi!
Przy wysokotransakcyjnych systemach rozmiar logu tekstowego przy ustawieniu log_min_duration_statement na 0 potrafi przyrastać w bardzo szybkim tempie, liczonym nawet w gigabajtach na minutę. Dlatego dla niektórych systemów przestawia się tę wartość na nieco wyższą, np. 60000, co oznacza zbieranie instrukcji SQL trwających jedynie powyżej minuty. Należy jednak pamiętać, że dla tych testów kluczowe jest zebranie wszystkich możliwych instrukcji, które mogą pojawić się w systemie, bez względu na ich czas trwania. Ustawiając parametr log_min_duration_statement na wartość wyższą od zera ryzykujemy zmniejszeniem dokładności naszych testów.
Odtwarzanie bazy PostgreSQL
Zanim przystąpimy do testów, konfigurujemy logowanie na serwerze testowym tak, żeby łatwo można było wychwycić błędy wynikające z migracji. Pomocne tutaj jest inne narzędzie, pgBadger, które także parsuje logi tekstowe, ale nie przekształca ich tak jak pgreplay do formy umożliwiającej ich odegranie, lecz generuje raport html zawierający m.in. zagregowane błędy, które wystąpiły w instancji. Wymaga on ustawienia następujących parametrów:
log_min_duration_statement = 0
log_line_prefix = '%t [%p]: [%l-1] db=%d,user=%u,app=%a,client=%h '
logging_collector = on
log_checkpoints = on
log_connections = on
log_disconnections = on
log_lock_waits = on
log_temp_files = 0
log_autovacuum_min_duration = 0
log_error_verbosity = default
lc_messages='C'
Wystarczy je skopiować i wkleić na końcu pliku postgresql.conf. Następnie wykonujemy reload klastra testowego w celu załadowania nowej konfiguracji logowania i rotujemy plik loga:
SELECT pg_rotate_logfile();
Możemy już przystąpić do odtwarzania środowiska z produkcji na świeżym serwerze testowym. W przykładzie powyżej do zrobienia kopii został użyty format „plain” więc odtworzenie polega na przekierowaniu zawartości pliku do psql-a. Tworzymy również nową bazę w instancji o tej samej nazwie co baza produkcyjna, do której będziemy wgrywać kopię:
createdb nazwa_bazy
psql -f dump_ze_starej_wersji.dmp nazwa_bazy 2> bledy
Jeśli w klastrze produkcyjnym istnieją inne bazy, należy je również utworzyć na środowisku testowym. Już na tym etapie mogą pojawić się niezgodności. Warto więc podczas odtwarzania przekierować błędy do innego pliku, aby w razie jakichkolwiek problemów, naprawić je przed odtwarzaniem ruchu produkcyjnego.
Odgrywanie loadu
W momencie, kiedy mamy już do dyspozycji zgraną wersję bazy z produkcji oraz logi tekstowe zebrane przez żądany okres możemy przystąpić do parsowania logów narzędziem pgreplay. Tutaj mamy dwie opcje:
1. parsowanie i odgrywanie w jednym etapie;
2. lub sparsowanie do postaci przejściowej, gotowej do odgrywania, a następnie odegranie na środowisku testowym.
Każda z opcji ma wady i zalety, polecam więc dobranie odpowiedniej dla siebie. Sposób pierwszy prawdopodobnie będzie wygodniejszy przy jednorazowym odtwarzaniu, jeśli planujemy kilka cykli napraw i odgrywania lub dodatkowo testy wydajnościowe prawdopodobnie lepsza jest opcja nr 2.
Najprostsze odtworzenie loadu produkcyjnego wygląda następująco:
pgreplay10 -c postgresql-Thu.csv
Jako opcję podajemy:
-c log jest w postaci csv
oraz nazwę pliku loga
Wyniki
Po wykonaniu testu parsujemy tym razem logi z serwera testowego drugim narzędziem – pgBadgerem:
pgbadger postgresql-Thu.log -o raport.html
Jako wejście podajemy plik loga z serwera testowego, po przełączniku -o nazwę wyjściowego raportu z rozszerzeniem html. W raporcie, w zakładce „Events” znajdzie się szczegółowy wykaz błędów, które wystąpiły podczas odgrywania ruchu produkcyjnego na nowej wersji PostgreSQL. Uzyskujemy zatem szczegółowy wykaz wszystkich niezgodności wynikający z podniesienia wersji bazy.
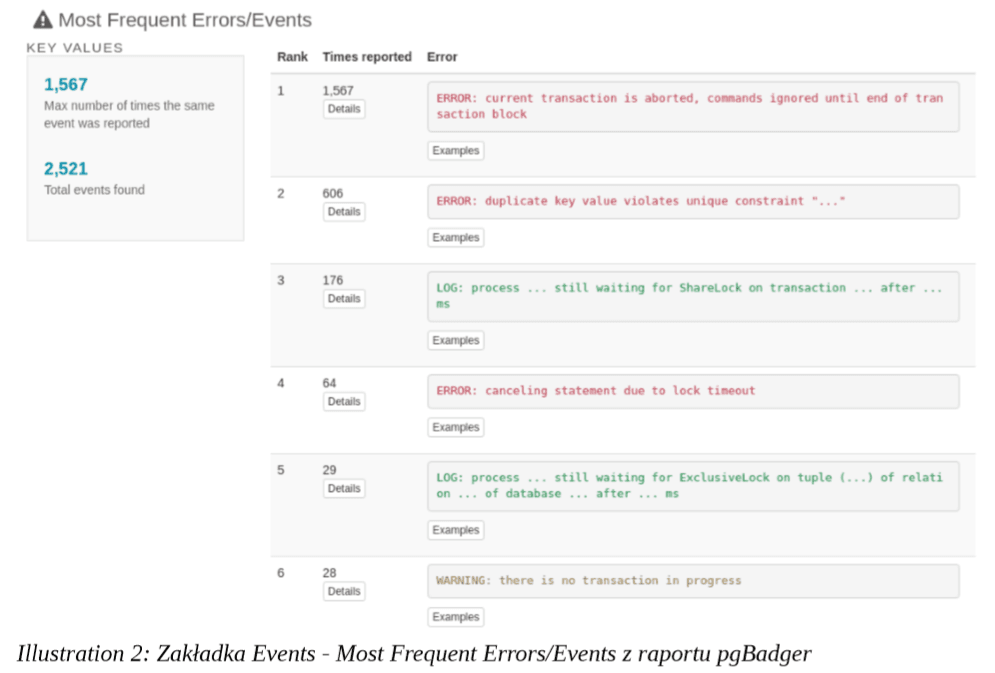 Illustration 2: Zakładka Events raportu pgBadger
Illustration 2: Zakładka Events raportu pgBadger